I have sat in enough control tower demos to last a lifetime. The story is always the same. Here is your shipment, here is the delay, here is the alert. The dashboards are beautiful. The data is real-time. And the person watching it still has to open three systems, call two people, and send an email before anything actually happens. By then, the window has usually closed.
The industry has spent billions on visibility. Tracking shipments, monitoring inventory, connecting supplier portals - the plumbing works. And yet, when a port congestion event cascades into a stockout, when a tier-2 supplier quietly goes dark, organisations still scramble. The data was there. The dashboards were live. The alerts fired. The response was still slow, fragmented and reactive.
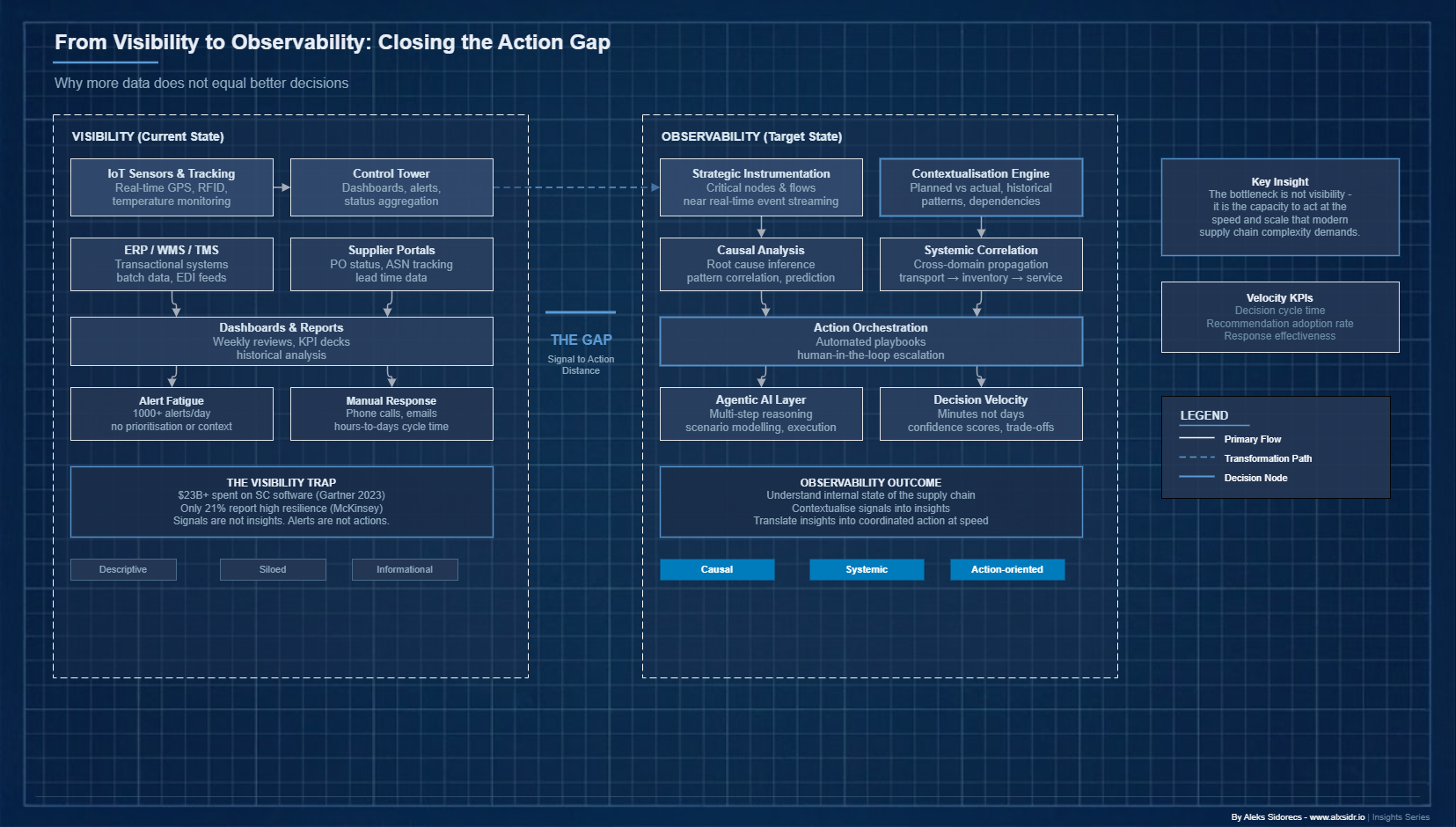
The problem is not visibility. The problem is that visibility was never enough. What separates organisations that absorb shocks from those that are paralysed by them is not how much data they can see. It is the quality of understanding they generate from it, and how fast that understanding becomes action.
This is supply chain observability - a discipline borrowed from software engineering and adapted for physical and digital supply chains. Most organisations have not built it in any coherent way. It is not a product you buy. It is a capability you build.
The Visibility Trap
The supply chain software market exceeded $23 billion in 2023 (Gartner) and keeps growing at roughly 10% a year. A massive portion of that spend goes to real -time tracking, control tower platforms, supplier collaboration portals and IoT monitoring. By any measure, large enterprises now have access to more operational data than at any point in history.
And here is the thing. A McKinsey survey found that only 21% of supply chain executives described their organisations as having "high resilience" - the ability to anticipate, absorb and recover from disruptions faster than competitors. The majority reported that even when they detected disruptions early, the time to diagnose root causes, align stakeholders and execute a response was far longer than the detection itself.
I have seen this pattern across every turnaround programme I have run. The data is there. The problem is what happens next.
A dashboard showing that a container vessel is delayed by four days at Ningbo does not tell you which SKUs are at risk, which customer commitments are threatened, whether safety stock at the regional DC is sufficient to bridge the gap, or what the optimal reallocation looks like across a network of 14 fulfilment points. Each of those questions requires a different data join, a different analytical model and, typically, a different team. By the time they align, the problem has compounded.
Practitioners call this "alert fatigue with analysis paralysis." The system generates more signals than the organisation can meaningfully process. The cognitive load of triaging and contextualising those signals consumes more capacity than the actual problem-solving.
Visibility tells you something is happening. It does not tell you what it means, why it is happening, what will happen next, or what you should do about it. That gap - between observation and action - is exactly where observability sits.
What Observability Actually Means
The term comes from control theory and was brought into software engineering by teams at Twitter, Netflix and Google building distributed systems at scale. In that context, observability is the ability to infer the internal state of a system from its external outputs.
Not just knowing that something is wrong, but understanding *why* it is wrong and *where* in a complex architecture the fault originates. Software engineers use three pillars: metrics (quantitative measurements over time), logs (discrete event records) and traces (end-to-end records of how a request flows through a system). Together, they reconstruct the causal chain of a failure. Not just the symptoms.
Here is why this matters for supply chains. Supply chains are distributed systems. They have nodes (factories, warehouses, ports, carriers), flows (materials, information, money) and emergent behaviours that arise from thousands of actors and events interacting. The failure modes are structurally identical to distributed software: cascading dependencies, latency amplification, state inconsistencies and feedback loops that stay invisible until they become catastrophic.
Supply chain observability is the capability to understand the internal state of your supply chain - its stresses, its dependencies, its failure trajectories - from the data it generates. It goes beyond visibility in three ways that matter.
It is causal, not just descriptive. Visibility tells you inventory at a given node is below safety stock. Observability tells you this is the third consecutive replenishment cycle where actual lead time from that supplier exceeded the plan by more than 20%, that this pattern correlates with a seasonal capacity constraint at the supplier's logistics partner, and that the same pattern preceded a stockout 14 months ago. The difference between a metric and an insight is causal context.
It is systemic, not siloed. Most visibility tools are built around functional domains - transportation visibility, inventory visibility, supplier visibility. Observability requires cross-domain correlation. A delay in inbound transport affects inventory positions, which affects production scheduling, which affects outbound commitments, which affects customer service levels. One event. Five functions. Observability surfaces that propagation.
It is action-oriented, not informational. The output of observability is not a better dashboard. It is a decision. A recommended action with confidence level, trade-off analysis and downstream implications - enough context for a human operator or an autonomous agent to execute. This is the connection to velocity: observability compresses the distance between signal and response.
The Three Layers of Supply Chain Observability
Building this requires thinking in layers. Each one answers a different question.
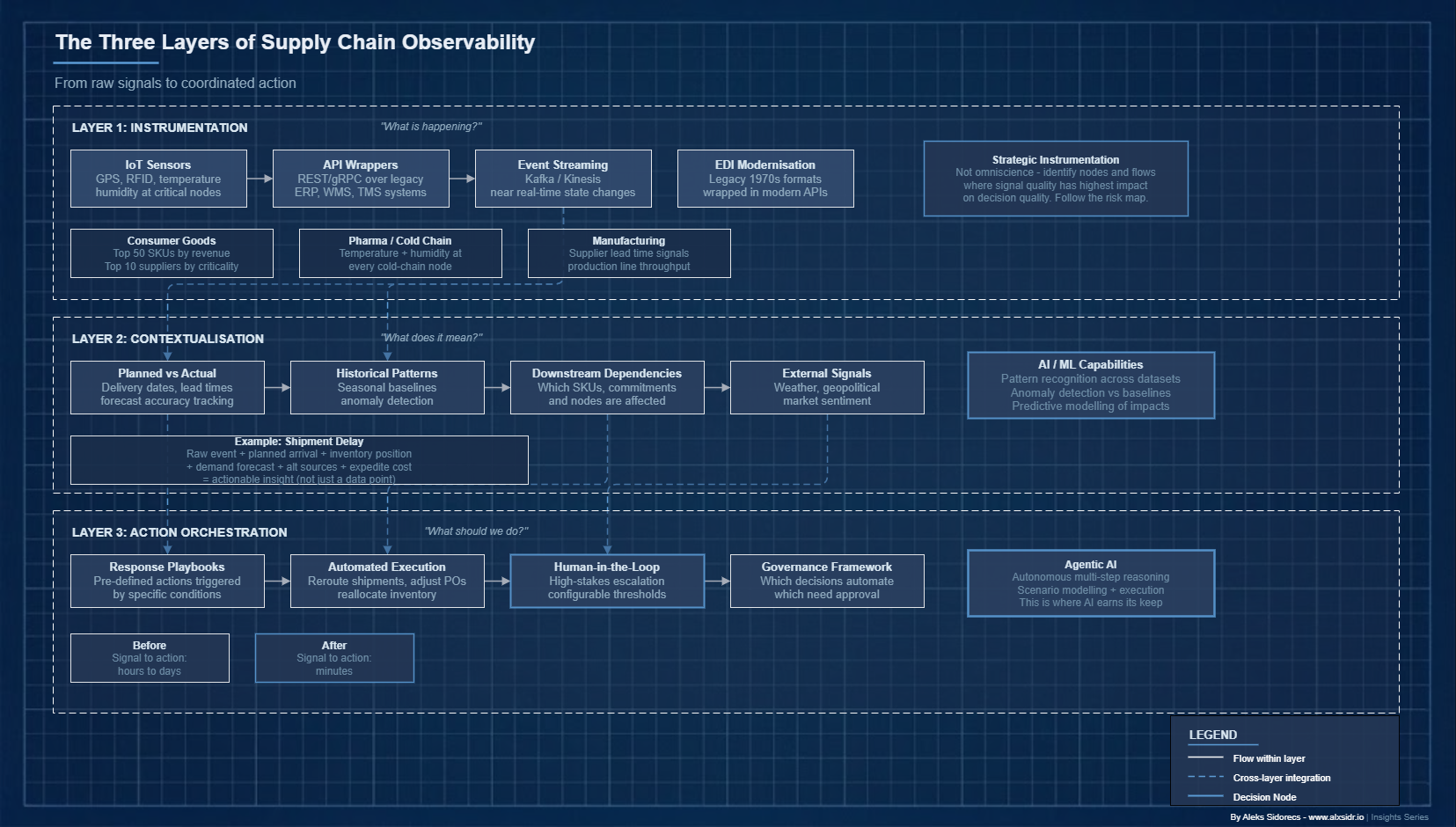
Layer One: Instrumentation
Before you can observe, you must instrument. Every node, flow and transaction in your supply chain needs to generate structured, timestamped, machine-readable data. In practice, this is harder than it sounds. Many supply chains still run on batch data transfers, manual status updates, PDF documentation and EDI messages designed in the 1970s.
The instrumentation layer is about closing those gaps. Not by replacing every legacy system overnight - that is a multi-year fantasy. By wrapping them in APIs, deploying IoT sensors at critical nodes and establishing event-streaming infrastructure that captures state changes in near real time.
The goal is not omniscience. It is strategic instrumentation - identifying the nodes and flows where signal quality has the highest leverage on decision quality. For a consumer goods company, that might mean real-time visibility into the top 50 SKUs by revenue and the top 10 suppliers by criticality. For a pharma distributor, temperature and humidity monitoring at every cold-chain node. The instrumentation strategy should follow the risk map.
Layer Two: Contextualisation
Raw events become meaningful signals only when they are contextualised. This is where most organisations fall short. Contextualisation means enriching event data with the information needed to assess its significance: planned versus actual comparisons, historical patterns, downstream dependencies, constraint information and external signals.
A shipment delay event needs context. Planned arrival date. Current inventory position at the destination. Demand forecast for the relevant SKUs. Lead time to alternative sources. Cost of expediting. Without that context, the event is a data point. With it, it becomes something you can act on.
This is where machine learning and AI start earning their keep. Pattern recognition across large historical datasets, anomaly detection relative to seasonal baselines, predictive modelling of downstream impacts - these are contextualisation capabilities that are increasingly accessible through modern platforms and purpose-built AI tools.
Layer Three: Action Orchestration
This is where observability connects to velocity. Action orchestration translates a contextualised insight into a coordinated response - automatically where appropriate, with human-in-the-loop escalation where the stakes warrant it.
This layer is what most supply chain technology architectures have not built. The dominant model is still one where an insight surfaces in a dashboard, a human analyst interprets it, escalates to a decision-maker, who then responds through phone calls, emails and manual system updates. Signal to action: hours or days.
Action orchestration compresses that cycle.
Pre-defined response playbooks triggered by specific conditions. System authority and integration depth to execute responses - rerouting a shipment, adjusting a purchase order, reallocating inventory across nodes - without manual intervention at every step.
And a governance framework defining which decisions can be automated, which need human approval and which require escalation. This is precisely where agentic AI - systems capable of autonomous, multi-step reasoning and action - is beginning to have real impact.
Agentic AI as the Observability Engine
Large language models and agentic AI architectures have introduced a new class of capability that fits the observability problem particularly well. Where traditional rule-based automation requires explicit programming of every condition and response, agentic systems reason across complex, ambiguous situations, synthesise information from multiple sources and generate contextualised recommendations or execute actions.
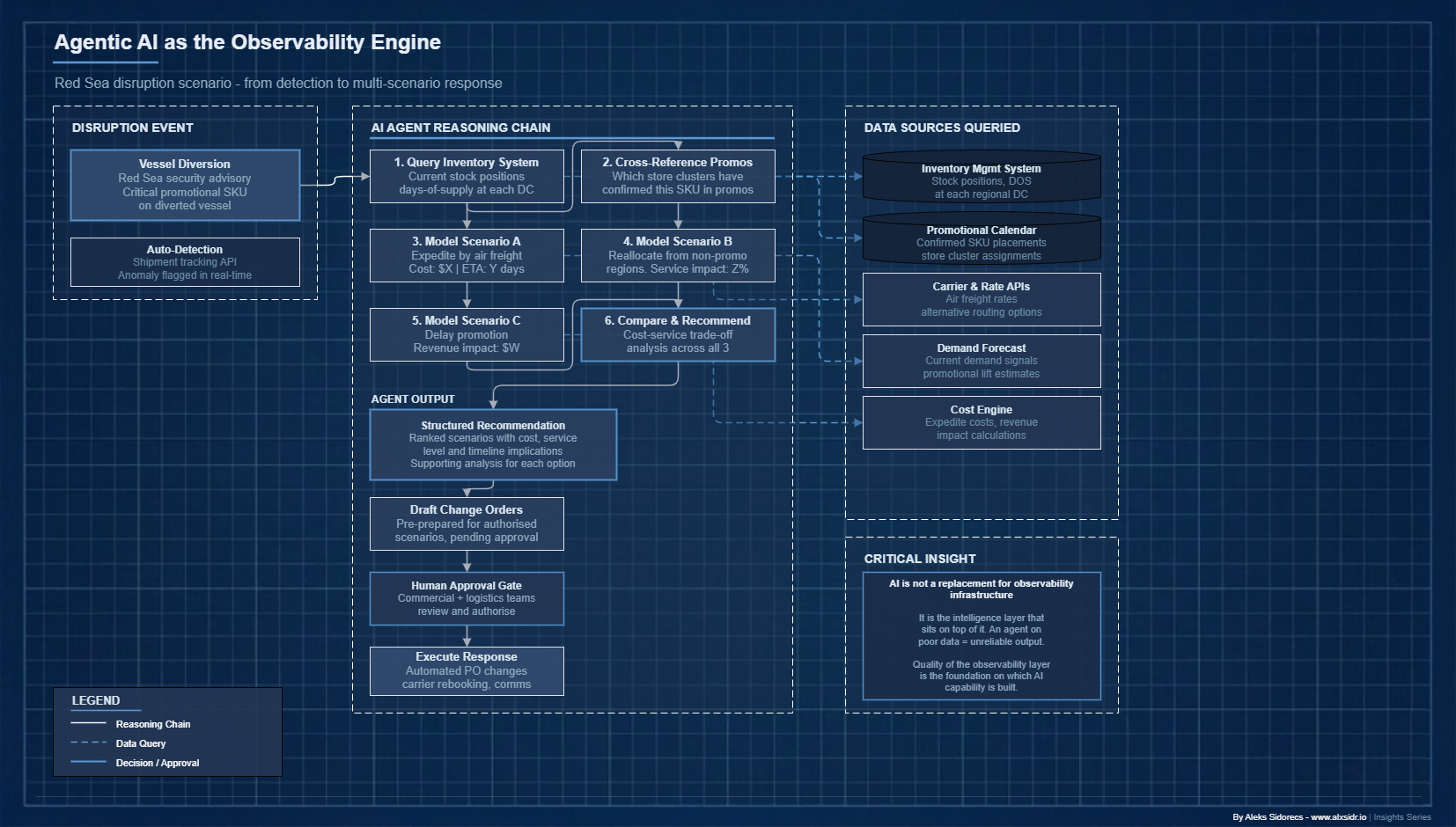
Here is a concrete scenario. A major retailer's supply chain AI agent monitors inbound shipment data and detects that a vessel carrying a critical promotional SKU has been diverted due to a Red Sea security advisory. The agent does not just flag the delay. It queries the inventory management system to assess stock positions and days-of-supply at each regional DC. It cross-references the promotional calendar to identify which store clusters have confirmed the SKU in upcoming promotions.
It models three response scenarios - expedite by air freight, reallocate existing inventory from non-promotional regions, or delay the promotion - and calculates the cost and service-level implications of each. It drafts a recommendation with supporting analysis for the commercial and logistics teams, and prepares change orders for the scenarios it is authorised to execute pending human approval.
This is not hypothetical. Unilever, Maersk and Walmart have publicly discussed investments in AI-driven supply chain decision support that operate along exactly these lines. The technology stack - real-time data integration, predictive modelling and LLM reasoning - is production-ready today. The organisational and governance challenges are the hard part.
The critical point: agentic AI is not a replacement for observability infrastructure. It is the intelligence layer that sits on top of it. An AI agent running on incomplete, inconsistent or poorly contextualised data will produce unreliable output. The quality of the observability layer - instrumentation, contextualisation, data governance - is the foundation. Organisations that skip that foundation will find their AI initiatives underperform. I have watched it happen.
Why Most Organisations Are Not Ready
Despite the logic, most organisations face structural barriers to building observability. Four stand out.
Data fragmentation and quality. The average large enterprise runs supply chain data across dozens of systems - ERPs, WMS platforms, TMS tools, supplier portals, demand planning systems and carrier APIs - that were not designed to interoperate. Data definitions are inconsistent. What one system calls a "confirmed order" another calls a "planned shipment." Timestamps are unreliable. Master data is duplicated and divergent. Building observability on this foundation requires serious investment in data integration, master data management and quality assurance. Unglamorous work. Non-negotiable.
Organisational silos. Observability is inherently cross-functional. Transportation, inventory, procurement, commercial and finance teams need to share data, align on definitions and coordinate responses. In most large organisations, these functions sit in separate reporting lines with separate KPIs, separate systems and limited incentive to collaborate. I spent the better part of two years at Holcim working through exactly this problem across 80 countries. The political and organisational work of building shared infrastructure is often harder than the technical work.
Talent gaps. Building and operating observability requires a combination of supply chain domain expertise, data engineering skills and analytical capability that is genuinely rare. The supply chain function has traditionally attracted operational and commercial talent, not data engineers. Closing this gap requires deliberate hiring, technology partnerships and capability investment - not just tool procurement.
Governance and trust. As observability matures into action orchestration - and particularly as AI agents begin executing or recommending consequential decisions - governance becomes critical. Who is accountable when an automated decision goes wrong? What are the escalation thresholds? How do you maintain human oversight without recreating the bottlenecks that automation was supposed to eliminate? These are not technical questions. They are organisational ones. Most supply chain functions have not yet built the frameworks to answer them.
A Practical Roadmap
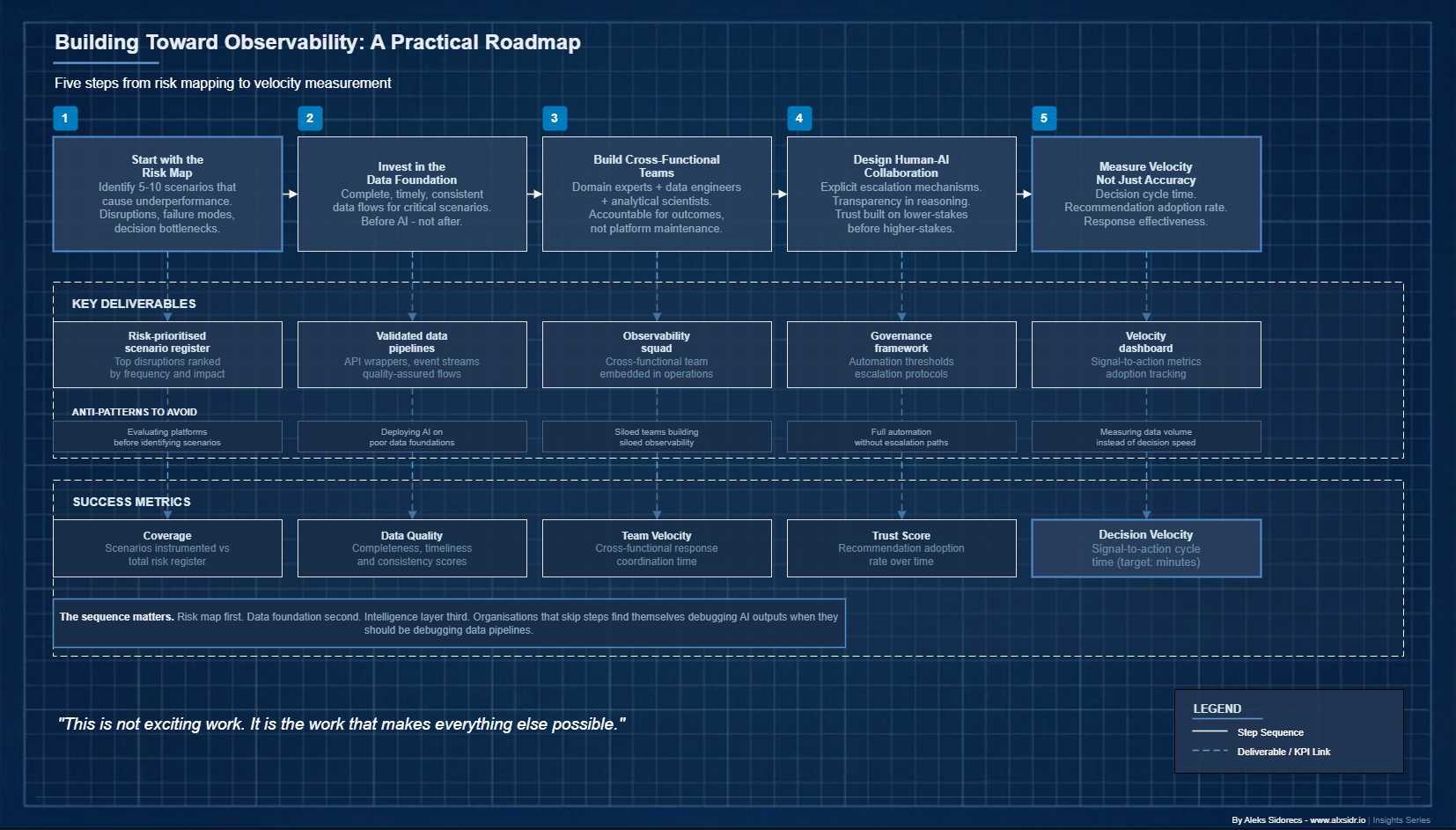
For supply chain leaders who recognise the gap, the path forward is neither simple nor linear. But it is navigable.
Start with the risk map, not the technology catalogue. Do not evaluate platforms first. Identify the five to ten scenarios that most frequently cause your supply chain to underperform - the disruption types, the failure modes, the decision bottlenecks that consume the most management attention. Direct observability investment at those scenarios. This ensures the capability is grounded in operational value, not technical elegance.
Invest in the data foundation before the intelligence layer. The temptation is to deploy AI tools on top of existing data infrastructure and hope that intelligence compensates for quality problems. It does not. Before investing in advanced analytics or agentic AI, make sure the data flows feeding your critical scenarios are complete, timely and consistent. This is not exciting work. It is the work that makes everything else possible.$
Build cross-functional observability teams. The most effective models combine supply chain domain experts with data engineers and analytical scientists in cross-functional teams accountable for specific operational outcomes - not just platform maintenance. These teams should be embedded close enough to operations to understand the business context, and empowered enough to drive the coordination that observability requires.
Design for human-AI collaboration, not replacement. The action orchestration layer needs explicit human-in-the-loop mechanisms for high-stakes decisions. This is not just risk management. It is change management. Supply chain professionals who trust that the system will escalate appropriately are more likely to act on its recommendations confidently. Building that trust requires transparency, clear thresholds and a track record on lower-stakes decisions before extending autonomy to higher-stakes ones.
Measure velocity, not just accuracy. The KPIs that matter are not traditional supply chain metrics. Decision cycle time - how long from signal to response. Recommendation adoption rate - what proportion of system recommendations are acted on, and why. Response effectiveness - how well the executed response matched the predicted outcome. These tell you whether your observability capability is actually shortening the distance between data and action.
The Distance Between Signal and Action
Visibility was the right answer for its time. In an era of limited data and limited connectivity, knowing what was happening across a global network was genuinely valuable. But the question has changed. The data is there. The signals are firing. The dashboards are live. The question now is whether you can understand your supply chain - deeply enough, quickly enough and comprehensively enough to act before the window closes.
Observability closes that gap. It sits between data and action, between signal and response, between knowing and doing. It is not a dashboard upgrade. It is an architectural commitment to building supply chains that can reason about themselves - and increasingly, to deploying AI systems that can do that reasoning at a speed and scale that human teams cannot match alone.
I keep coming back to the same observation from twenty years of doing this work: the organisations that win are not the ones with the most data. They are the ones that compress the distance between seeing a problem and doing something about it. That distance is not a technical parameter. It is a strategic variable. And I am not sure most supply chain leaders have fully grasped what happens when their competitors figure that out first.