In this publication I explore why the OODA loop breaks down for autonomous systems - and what a fifth phase changes about how we model orchestration.
The Original Loop
Colonel John Boyd never published a paper on the OODA loop. He briefed it — hundreds of times, across thousands of slides, to Pentagon audiences who mostly missed the point. What they took away was a four-step cycle: Observe, Orient, Decide, Act. What Boyd actually meant was far more radical.
Boyd's central insight was that the Orient phase does most of the work. Orientation isn't just "assessing the situation" — it's the entire mental model through which you interpret reality. Your cultural traditions, previous experience, genetic heritage, analytical capacity, incoming information — all of it feeds into how you construct meaning from what you observe. The fighter pilot who wins isn't the one with faster reflexes. It's the one whose orientation is more accurate.
The pilot who cycles through the loop faster than the enemy controls the engagement. But the pilot whose model of reality is more accurate controls the war.
This is elegant for human combat. A fighter pilot observes, orients, decides, and acts — then immediately observes the result and begins the next cycle. The loop is fast because the human brain updates its model implicitly. You don't need a formal "learn" step because learning is baked into how humans process experience.
Machines don't work this way.
Where OODA Breaks for Agentic Systems
When you implement OODA as a software pattern for an autonomous agent, something subtle goes wrong. The agent observes, orients against its current model, decides, and acts — then loops back to observe again. On paper, this looks complete. In practice, the model that drives orientation stays static. The agent makes faster decisions each cycle, but it doesn't make better ones.
This is the gap I kept running into while designing orchestration solutions for supply chain and business operations. An agent that monitors carrier performance, for example, can cycle through OODA rapidly: observe a shipment delay, orient against expected transit times, decide to escalate, act by notifying the operations team. Fast. Reliable. And completely unable to recognise that its transit time expectations are wrong because market conditions shifted two weeks ago.
Boyd's implicit learning phase — the one humans do naturally between cycles — doesn't exist in code unless you build it explicitly.
OODAA: Observe, Orient, Decide, Act, Adjust
The extension is a single word: Adjust. After Acting, the system enters a structured phase where it evaluates what the action produced against what was expected, generates hypotheses about why gaps exist, researches those hypotheses, and updates the model that feeds orientation.
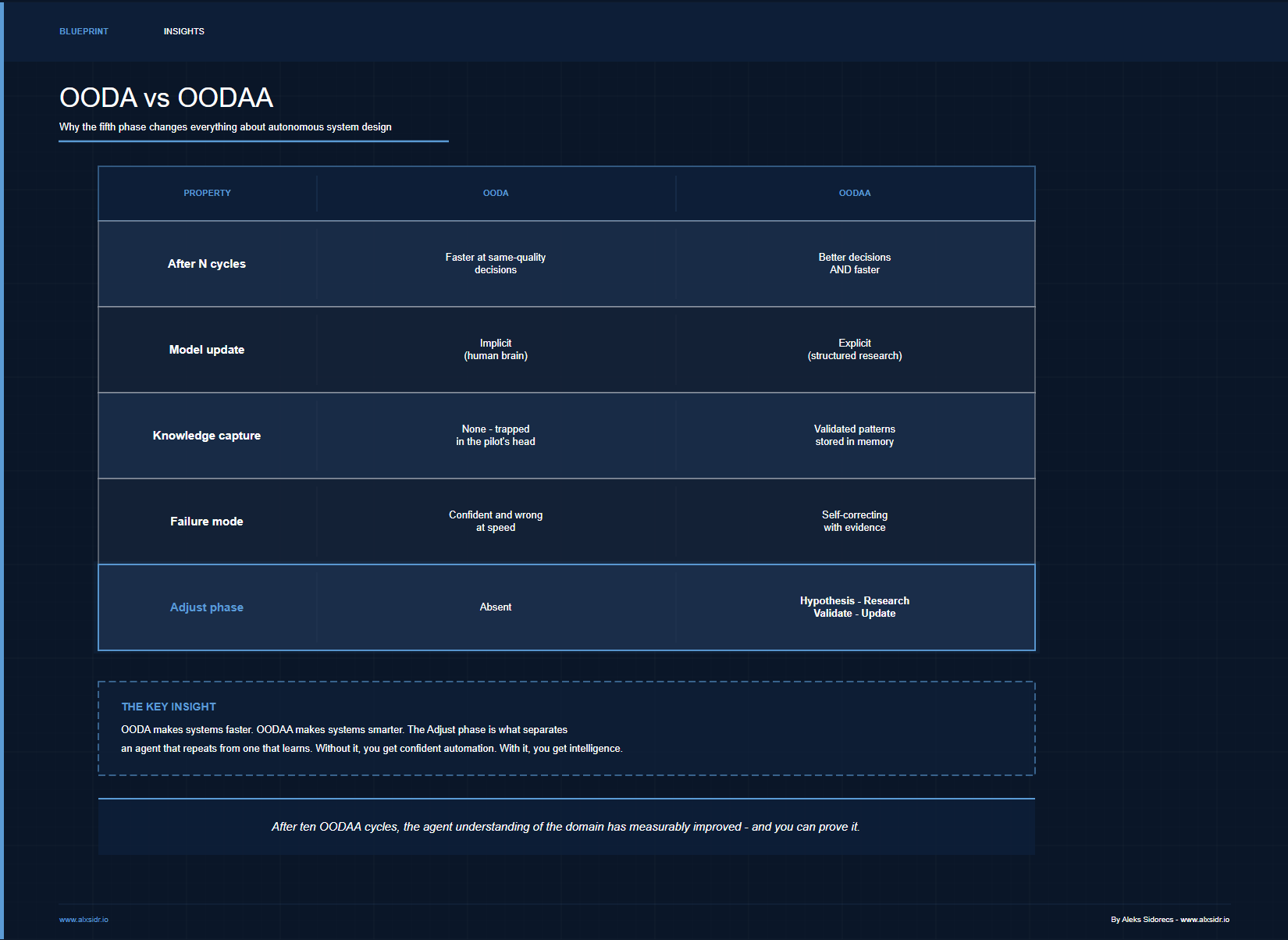
The difference between OODA and OODAA is the difference between a system that gets faster and a system that gets smarter. After ten OODA cycles, you have an agent that makes the same quality decisions more quickly. After ten OODAA cycles, you have an agent whose understanding of the domain has measurably improved — and you can prove it.
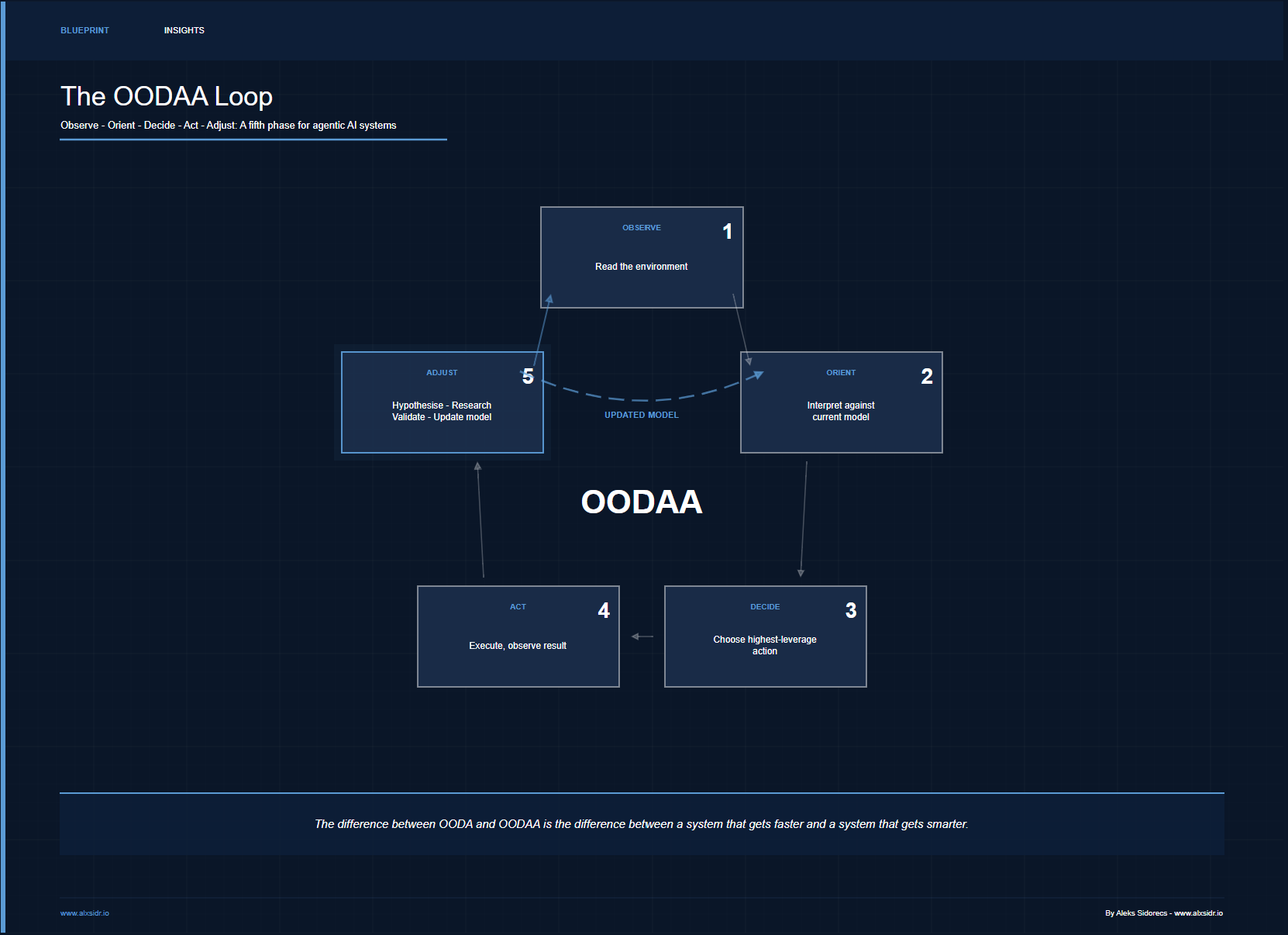
The difference between OODA and OODAA is the difference between a system that gets faster and a system that gets smarter. After ten OODA cycles, you have an agent that makes the same quality decisions more quickly. After ten OODAA cycles, you have an agent whose understanding of the domain has measurably improved - and you can prove it.
When plain OODA is enough
Not every agent needs a fifth phase. Short-lived, stateless tasks - formatting a document, routing a message, answering a lookup query - don't benefit from model updates because there's no model to improve. OODAA adds latency and compute cost per cycle (hypothesis generation, research, validation are all LLM calls). The framework earns its keep on long-running agents where the environment shifts faster than you can re-deploy, and where the cost of a wrong orientation compounds over time. If your agent runs once and discards its state, OODA is perfectly fine.
How This Shapes My Orchestration Modeling
OODAA isn't academic. It directly shapes how I model agentic solutions. In my lab, every orchestration system I've been experimenting with follows three principles that come directly from the framework.
1. Orientation is the critical phase, not action
Most agent architectures focus on action - tool use, API calls, task execution. Boyd was clear that orientation matters more, and this holds even more strongly for autonomous systems. His original diagram included feedback arrows from Orient directly to Act - bypassing Decide entirely - for situations where a well-oriented pilot acts on intuition. That shortcut is dangerous for machines unless the model feeding orientation is continuously validated. OODAA makes those implicit shortcuts safer because the Adjust phase keeps the underlying model honest. When I design an orchestration solution, the Orient phase gets the most design attention: what data feeds into the agent's world model, what objectives it measures against, what assumptions it holds. A well-oriented agent with limited tools outperforms a poorly-oriented agent with extensive capabilities every time.
2. Every decision stores its rationale
In a pure OODA implementation, the agent decides and moves on. In OODAA, the Decide phase produces an ActionAgenda that includes why each action was chosen. This isn't for human audit (though it helps) - it's for the Adjust phase. Without stored rationale, the system has no way to evaluate whether its reasoning was correct after the fact. This is the difference between an agent that acts on instinct and one that builds institutional knowledge.
3. The Adjust phase generates falsifiable hypotheses
This is where OODAA diverges most sharply from traditional agent design. The Adjust phase doesn't just log results - it generates specific, testable hypotheses about why performance gaps exist. A manufacturing outreach agent that sees low reply rates doesn't just record "low performance." It hypothesises: subject lines reference carrier portals (freight-specific language) rather than production floor language (manufacturing-relevant signals). It then researches this hypothesis, validates or invalidates it against data, and either promotes the finding to long-term memory or logs it as negative evidence. A portfolio monitoring agent that sees unexpected drawdowns doesn't just flag the loss - it hypothesises whether the correlation structure between holdings has shifted and tests that against recent market data. The system's understanding compounds with every cycle, regardless of domain.
The deployment ceiling is not the model. It's the organisation. But with OODAA, the system itself becomes the organisation's learning capacity.
From Control Towers to Intelligent Orchestration
The supply chain industry has spent a decade building "control towers" - dashboards that aggregate data and surface exceptions. These are, at best, OODA without the D. They observe and orient, but decisions and actions remain entirely human. The next generation of platforms tries to add decision automation, but without the Adjust phase, these systems are brittle. They work until the environment shifts, and then they fail confidently.
OODAA is the operating model for what I call Intelligent Orchestration - systems that don't just monitor and react, but learn and adapt. The Agentic Target Operating Model I've been experimenting with in my lab treats the Adjust phase as the primary source of competitive advantage. Any organisation can deploy agents that observe, orient, decide, and act. The one that implements a structured Adjust phase accumulates validated domain knowledge that no competitor can replicate without running the same cycles.
This extends naturally to multi-agent systems. When multiple OODAA agents share a common memory layer, findings from one agent's Adjust phase propagate to others. A logistics agent that discovers a corridor disruption updates shared orientation data that a procurement agent reads in its next cycle. The system learns as a network, not as isolated loops. This is what separates orchestration from mere automation - the agents don't just coordinate actions, they coordinate understanding.
Boyd designed his loop for a single pilot in a single engagement. OODAA is designed for systems that run continuously, learn incrementally, and improve the understanding that drives every decision - not just the speed at which decisions are made.